Bot Building with SPS
Thu, Aug 15, 2013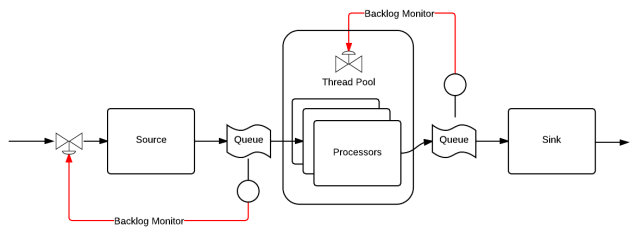
In 2003, I was writing lots of bots, and a pattern emerged. I thought, “There’s probably already a name for this” as I put the finishing touches on my new bot-building framework. “I dub thee: SPS — Source, Processors, Sink. Very catchy!” It turns out that I’d created an example of SEDA — Staged Event-driven Architecture.
SPS has three stages connected by two bounded queues. There’s almost always a single source that deposits items to be processed into the input queue. In the second stage, items in the input queue are consumed by a large number of processors. When a processor finishes its work, the result is put into the output queue. Finally, the sink (normally, just one) pulls results from the queue and sends them on to their final destination.
Monitoring the size of the queues tells us a lot about the state of the system. As Matt Welsh, the creator of SEDA, writes,
“The most important contribution of SEDA, I think, was the fact that we made load and resource bottlenecks explicit in the application programming model. Regardless of how one feels about threads vs. events vs. stages, I think this is an extremely important design principle for robust, well-behaved systems. SEDA accomplishes this through the event queues between stages, which allow the application to inspect, reorder, drop, or refactor requests as they flow through the service logic. Requests are never “stalled” somewhere under the covers — say, blocking on an I/O or waiting for a thread to be scheduled. You can always get at them and see where the bottlenecks are, just by looking at the queues.”
Let’s say the input queue is full; our source consistently times-out while offering items to the queue. Processing is a bottleneck. If more capacity exists, we can increase the number of processors. Otherwise, we’ll throttle input while we attempt to optimize the processor code. If this isn’t possible, we purchase more cores or grudgingly accept that we’ve discovered the maximum processing rate.
OK. The number of processors is tuned, things are working great, and now the output queue is full. Is the sink performing a blocking operation? Did something downstream fail or suddenly become slower? We at least know where to look.
This architecture is extremely flexible and testable. We’d like to build an image processor? The source supplies image URLs. A processor takes an image URL from the queue, attempts to download it and, if successful, creates a thumbnail and enqueues it. The sink writes thumbnails (somewhere, TBD). For performance testing, we can plug-in a dummy source that continuously keeps input the queue full with a test URL and a sink that extracts and discards results from the output queue. We can then adjust the number of processors to find the maximum processing rate. Now that we know the processor’s performance characteristics, we can replace the source and sink with functional ones. Maybe URLs come from a database and the sink writes thumbnails to Amazon S3?
Another nice property is that the only compile-time knowledge required to connect components is a shared set of messages. If components produce and consume the same objects, they are interchangeable. By carefully designing the shared message library, I can put together bots like Tinkertoys!™